Troubleshooting
We have extended our troubleshooting documentation to cover more common issues and questions. If you have any suggestions for this please open an issue here.
Security Engine
Remediation Components
CTI
Community support
Please try to resolve your issue by reading the documentation. If you're unable to find a solution, don't hesitate to seek assistance in:
FAQ
Security Engine
What is CrowdSec Security Engine ?
CrowdSec Security Engine is a open-source security software. See the overview.
I've installed the Security Engine, it detects attacks but doesn't block anything ?!
Yes, the Security Engine is in charge of detecting attacks, and Remediation Component are applying decisions. If you want to block the detected IPs, you should deploy a Remediation Component, such as the ones found on the hub !
What language is it written in ?
CrowdSec Security Engine is written in Golang.
What resources are needed to run Security Engine ?
Security Engine itself is rather light, and in a small to medium setup should use less than 100Mb of memory.
During intensive logs processing, CPU is going to be the most used resource, and memory should grow slightly.
What is the performance impact ?
As the Security Engine only works on logs, it shouldn't impact your production. When it comes to remediation components, please refer to their documentation.
What license is provided ?
The Security Engine and Remediation Components are provided under MIT license.
How fast is it
The Security Engine can easily handle several thousands of events per second on a rich pipeline (multiple parsers, geoip enrichment, scenarios and so on). Logs are a good fit for sharding by default, so it is definitely the way to go if you need to handle higher throughput.
If you need help for large scale deployment, please get in touch with us on the Form, we love challenges ;)
How to set up proxy
Setting up a proxy works out of the box, the net/http golang library can handle those environment variables:
HTTP_PROXYHTTPS_PROXYNO_PROXY
For example:
export HTTP_PROXY=http://<proxy_url>:<proxy_port>
Systemd variable
On Systemd devices you have to set the proxy variable in the environment section for the CrowdSec service. To avoid overwriting the service file during an update, a folder is created in /etc/systemd/system/crowdsec.service.d and a file in it named http-proxy.conf. The content for this file should look something like this:
[Service]
Environment=HTTP_PROXY=http://myawesomeproxy.com:8080
Environment=HTTPS_PROXY=https://myawesomeproxy.com:443
Environment=NO_PROXY=127.0.0.1,localhost,0.0.0.0
After this change you need to reload the systemd daemon using:
systemctl daemon-reload
Then you can restart CrowdSec like this:
systemctl restart crowdsec
Sudo
If you use sudo cscli, just add this line in visudo after setting up the previous environment variables:
Defaults env_keep += "HTTP_PROXY HTTPS_PROXY NO_PROXY"
Tor
You can configure cscli and crowdsec to use tor to anonymously interact with our API.
All (http) requests made to the central API to go through the tor network.
With tor installed, setting HTTP_PROXY and HTTPS_PROXY environment variables to your socks5 proxy, as well as setting NO_PROXY to local addresses to prevent LAPI errors, will do the trick.
Edit crowdsec systemd unit to push/pull via tor
[Service]
Environment="HTTPS_PROXY=socks5://127.0.0.1:9050"
Environment="HTTP_PROXY=socks5://127.0.0.1:9050"
Environment="NO_PROXY=127.0.0.1,localhost,0.0.0.0"
Running the wizard with tor
$ sudo HTTPS_PROXY=socks5://127.0.0.1:9050 HTTP_PROXY=socks5://127.0.0.1:9050 NO_PROXY=127.0.0.1,localhost,0.0.0.0 ./wizard.sh --bininstall
cscli
$ sudo HTTP_PROXY=socks5://127.0.0.1:9050 HTTPS_PROXY=socks5://127.0.0.1:9050 NO_PROXY=127.0.0.1,localhost,0.0.0.0 cscli capi register
How to report a bug
To report a bug, please open an issue on the affected component's repository:
How to disable the central API
To disable the central API, simply comment out the online_client section of the configuration file.
Why are some scenarios/parsers "tainted" or "custom" ?
When using cscli to list your parsers, scenarios and collections, some might appear as "tainted" or "local".
"tainted" items:
- Originate from the hub
- Were locally modified
- Will not be automatically updated/upgraded by
csclioperations (unless--forceor similar is specified) - Won't be sent to Central API and won't appear in the Console (unless
cscli console enable taintedhas been specified)
"local" items:
- Have been locally created by the user
- Are not managed by
csclioperations - Won't be sent to Central API and won't appear in the Console (unless
cscli console enable customhas been specified)
Which information is sent to your services ?
See CAPI documentation.
How to know if my setup is working correctly ? Some of my logs are unparsed, is it normal ?
Yes, Security Engine parsers only parse the logs that are relevant for scenarios.
Take a look at cscli metrics and understand what do they mean to know if your setup is correct.
You can take an extra step and use cscli explain to understand what log lines are parsed, and how. :
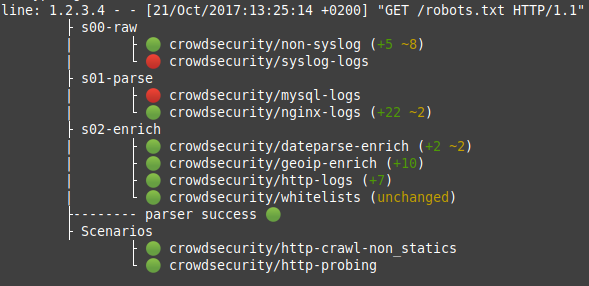
Why are X logs not parsed in cscli metrics ?
If you are facing logs that doesn't seem to be parsed correctly, please use cscli explain :
# cscli explain --log "May 16 07:50:30 sd-126005 sshd[10041]: Invalid user git from 78.142.18.204 port 47738" --type syslog
line: May 16 07:50:30 sd-126005 sshd[10041]: Invalid user git from 78.142.18.204 port 47738
├ s00-raw
| └ 🟢 crowdsecurity/syslog-logs (first_parser)
├ s01-parse
| ├ 🔴 crowdsecurity/iptables-logs
| ├ 🔴 crowdsecurity/mysql-logs
| ├ 🔴 crowdsecurity/nginx-logs
| └ 🟢 crowdsecurity/sshd-logs (+6 ~1)
├ s02-enrich
| ├ 🟢 crowdsecurity/dateparse-enrich (+2 ~1)
| ├ 🟢 crowdsecurity/geoip-enrich (+13)
| ├ 🔴 crowdsecurity/http-logs
| └ 🟢 crowdsecurity/whitelists (unchanged)
├-------- parser success 🟢
├ Scenarios
├ 🟢 crowdsecurity/ssh-bf
├ 🟢 crowdsecurity/ssh-bf_user-enum
├ 🟢 crowdsecurity/ssh-slow-bf
└ 🟢 crowdsecurity/ssh-slow-bf_user-enum
This command will allow you to see each parser behavior.
I want to add collection X : how to add log files, and how to test if it works ?
When adding a collection to your setup, the hub will usually specify log files to add.
Those lines need to be added in your acquisition file (/etc/crowdsec/acquis.yaml or /etc/crowdsec/acquis.d/myfile.yaml).
After restart, cscli metrics will allow you to see if lines are read and/or parsed.

